 Swift의 타입들 Types
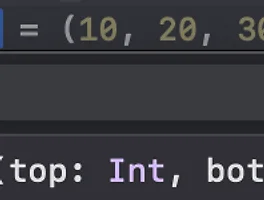
타입 Type타입이란 직역하면 어떤 부류의 형, 유형, 모양, 생김새 입니다.프로그래밍에서 타입은 값이 가질 수 있는 형태와 그 값에 대해 수행할 수 있는 연산을 정의하는 개념입니다.더 나누면 정적타입, 동적타입이 존재하지만 이 글에서는 다루지 않습니다 이 글에서는 Swift에서 존재하는 타입들을 살펴볼 것 입니다.더 자세한 내용은 Swift.org에 있습니다 Swift의 타입Swift의 타입은 두가지 종류가 있습니다.명명된 타입 (named type): 특정 이름을 부여할 수 있는 타입으로 클래스, 구조체, 열거형, 프로토콜, 배열, 딕셔너리, 옵셔널 모두 해당됩니다. 필요에따라 확장할 수 있습니다.복합 타입 (compound type): 정의된 이름이 없는 타입으로 함수와 튜플이 있습니다. 복합 타..
Swift의 타입들 Types
타입 Type타입이란 직역하면 어떤 부류의 형, 유형, 모양, 생김새 입니다.프로그래밍에서 타입은 값이 가질 수 있는 형태와 그 값에 대해 수행할 수 있는 연산을 정의하는 개념입니다.더 나누면 정적타입, 동적타입이 존재하지만 이 글에서는 다루지 않습니다 이 글에서는 Swift에서 존재하는 타입들을 살펴볼 것 입니다.더 자세한 내용은 Swift.org에 있습니다 Swift의 타입Swift의 타입은 두가지 종류가 있습니다.명명된 타입 (named type): 특정 이름을 부여할 수 있는 타입으로 클래스, 구조체, 열거형, 프로토콜, 배열, 딕셔너리, 옵셔널 모두 해당됩니다. 필요에따라 확장할 수 있습니다.복합 타입 (compound type): 정의된 이름이 없는 타입으로 함수와 튜플이 있습니다. 복합 타..




